モデルとテーブル
ユーザーが投稿した情報をビューに反映させるサイトのことを動的なサイトと言う。これを作成するには、情報を保存したり、またそれを引き出しビューに反映する仕組みが必要
モデルとテーブルについて
テーブルとモデルを連携させることで、DBから情報を引き出すことができる。
テーブル
テーブルとは、表形式の収納場所。データベースとは様々な情報を保存しておく場所だが、Pictweetを例にとると、ツイートやユーザーの情報がデータベースに存在するテーブルに整理して保存されている。

レコードとカラム
テーブルの横1行のことをレコード、縦1列のことをカラムと言う。1行目に項目名を入れたエクセルのようなイメージ。

通常、一つのデータベースの中に複数のテーブルがあり、この中にデータが保存されていく。つまり、データベースがあっても、テーブルがなければデータを保存できない。
テーブルの条件
RailsによるWebアプリケーション用のデータの保存場所であるテーブルには、2つの特徴がある。
1つめは、あるテーブル内レコードを特定するための値として、idというカラムが用意されること。通常、idカラムには整数が入る。
2つめは、行列によって区切られた1マスに入る値は1つでないといけないこと。
例えば、下記の表を見ると、上側はRDBにおけるテーブルだが、下側はただの無作為な表である。

DB設計
アプリケーション開発において大半のデータ(少なくとも永続的に使用されるデータ)はデータベース内に保持される。アプリケーションというのは、言ってみれば データの流通機構 である。どのようなデータをどういう形式で設計するかによって、品質は大きく左右される。
必要なテーブルやアプリケーションが快適に動作するように取り出しやすいデータベース構造をあらかじめ設計しておくことが必要。
これは近年のソフトウェア開発での主流の考え方で、 DOA と言う。
DOA
DOAとは、 データ中心アプローチ(Data Oriented Approach) という考え方。これは、文字通りシステムを作る際に、プログラムよりも前にデータ設計から始める方法論。DOAはサービス開発が効率的になるため近年主流になっている。
データベース設計の手順
データベース設計の手順は以下の通り。
- テーブルの抽出
- テーブルの定義
- テーブル構造を整理
- ER図の作成
テーブルを抽出
まずは、アプリケーションで使用するテーブルを全て抽出する。アプリケーションにおいてあらかじめ最低限必要なテーブルを洗い出しておく。そうすることで、アプリケーションの開発中に新たなテーブルを慌てて作ることをしなくて済む。途中でテーブルを追加するとテーブル間の関係性を見直す必要が出て、また設計から見直さなくてはならなくなる。
これから作成するpictweetでは、「user」「tweet」「comment」の3種類のデータを扱う。

テーブルの定義
テーブルを抽出した後は、各テーブルが持つカラムを決める。この段階でカラムを考える理由もテーブル抽出を行った理由と同じ。アプリケーション開発中にカラムを追加すると、アプリケーションのコードを書き直したり、ビューのデザインを変えたりする必要があり、非効率だからだ。
例えばこれから作成するpictweetでは、つぶやきには「タイトル」「画像」「内容」のデータを保持する設計になっている。したがって、それぞれをtweetsテーブルのtitleカラム・imageカラム・textカラムと定義する。
テーブル構造を整理
テーブル構造にはアプリケーションのパフォーマンスを著しく下げるやってはならない構造がある。
以下のようなテーブル構造になっていたら、きちんと整理し直すようにする。
1. 同じカラム名を1つのテーブルに複数作成
もし1つのテーブルに同じカラム名を複数作るようなテーブル構造になりそうになったら、必ず違うテーブルに保存するようにする。
以下は、記事に複数の画像を保存したい時の例。
articlesテーブル
| id | title | content | image1 | image2 | image3 | ... |
|---|---|---|---|---|---|---|
| 1 | タイトル1 | ... | photo.png | image.jpg | download.png | ... |
| 2 | タイトル2 | ... | screenshot.png | avatar.jpg | logo.png | ... |
| 3 | タイトル3 | ... | image3.png | takehumi.jpg | yamamura.png | ... |
このテーブル構造は悪い例。このままでは、記事に画像を追加する度にimageカラムを追加していかなくてはならなくなる。
これは、複数のimageに関するデータを1つのレコードが保持している状況。よく見ると articles:1 に対して image:多 の関係が成り立っている。つまりテーブル間の 1対多 で表現できることがわかる。従って、以下のようにテーブルを分ける。
articlesテーブル
| id | title | content |
|---|---|---|
| 1 | タイトル1 | ... |
| 2 | タイトル2 | ... |
| 3 | タイトル3 | ... |
imagesテーブル
| id | name | article_id |
|---|---|---|
| 1 | photo.png | 1 |
| 2 | image.jpg | 1 |
| 3 | download.png | 1 |
| 4 | screenshot.png | 2 |
| 5 | avatar.jpg | 2 |
| 6 | logo.png | 2 |
| 7 | image3.png | 3 |
| 8 | takehumi.jpg | 3 |
| 9 | yamamura.png | 3 |
こうすることによって、imagesテーブルにレコードを追加していけば記事に画像を際限なく保存することができる。
2. 予約語を使うことを避けよう
これからデータベースを作る際に一度はつまずいてしまうテーマに、予約語 がある。
予約語とは、MYSQL側で使用されるためテーブル名やカラム名に設定することができないよう決められている単語のこと。
予約語をテーブル名やカラム名に含んでしまうとエラーになる。あらかじめ、予約語の一覧を確かめておく必要がある。
ER図の作成
ER図とは、Entity-Relationship Diagramの略でテーブル同士の関係を視覚的にわかりやすく表した図。テーブルの整理をするとテーブルを細分化していく作業なので、物理的にテーブルの数が増えそれぞれのテーブルの関連性の見通しがつきにくくなる。
ER図は、以下のように IE表記法 という書き方。
これはペンでの走り書きでも構わない。
以下に例えば基本カリキュラムで作成したPictweetの各テーブルの関係をER図で表したものを示す。

上図について、
ユーザーとツイート間の関係性を見てみると、 ユーザー:1 に対して ツイート:0以上の多 という関係が表現されている。
同様にユーザーとコメント、ツイートとコメント間の関係性が図によって表現できている。
ER図を描くことでテーブル間の関係性が視覚的になり、分かりやすくなる。
テーブルの関連付け
1対多
1対多とはつまり、ひとつのものに対して複数のものが紐付いているような状態をいう。
1対多の関係性を作るには、 主従関係の従 に当たるテーブルに 所属するモデル_id という規則でカラム追加する。
【例】学級と生徒
例えば、生徒はどれかの学級に属している。それを表現するのに、生徒に所属先の学級の名札をつけるのが一般的である。
テーブルでもそれと同様の表現をする。
| カラム名(名札の形) | 値(クラス名) |
|---|---|
| 所属先のモデル名 + _id | 所属先のテーブルのid |
例えばこれから作成するpictweetでは、ユーザー:1に対してツイート:0以上の多という1対多の関係性である。

これは、以下のようにtweetsテーブルに所属先のusersテーブルのidをカラムとして保持させることで表現することができた。以下がその時のテーブルの例。
usersテーブル
| id | nickname | |
|---|---|---|
| 1 | saino | saino@gmail.com |
| 2 | takahashi | takahashi@gmail.com |
| 3 | yamamura | yamamura@gmail.com |
tweetsテーブル
| id | title | image | text | user_id |
|---|---|---|---|---|
| 1 | タイトル1 | photo.png | ... | 1 |
| 2 | タイトル2 | image.jpg | ... | 2 |
| 3 | タイトル3 | download.png | ... | 1 |
| 4 | タイトル4 | screenshot.png | ... | 3 |
| 5 | タイトル5 | avatar.jpg | ... | 3 |
データベースはWebアプリケーションの重要な構成要素のひとつである。続いて、RailsにおいてDBから情報を取得し利用する方法。
モデル
モデルとは、Railsの中でデータベースへのアクセスをはじめとする情報のやりとりに関する処理を担当しているパートで、実体は1つのクラスが定義された◯◯.rbというファイル。
モデルの使い方
ビューでデータベースに保存されているデータを表示するためには、コントローラでモデルを利用してテーブルからデータを引き出し、ビューに渡す。

基本的に、モデルはapp/models以下の階層に設置される。
【例】
- app
- models
- モデルファイル
- models
以下は、モデルのファイルの中身の例。
【例】
sample.rb
1 2 3 4 5 6 |
class Sample
def test
end
end
|
Sampleというクラスが書かれている。モデルを担当するクラスのことをモデルクラスと言う。例の場合は、Sampleというクラスがモデルクラスになる。
テーブルとモデルの結びつきは、名前で決定する
情報は、テーブルに保存される。Railsからあるテーブルに保存された情報を引き出す際は、そのテーブルに対応するモデルクラスを用意する。対応関係は、テーブルとモデルクラスの名前によって決定する。
モデルの命名規則
Railsでは、ファイルやテーブルなどの命名を規則に従った形にする必要がある。モデルとテーブルに関する命名規則は以下のようになっており、これに従えばテーブルとモデルが結びつく。
| 種類 | 概要 | 名前例 |
|---|---|---|
| モデルクラス名 | 先頭は大文字、単数形 | Tweet |
| モデルクラスのファイル名 | 先頭は小文字、単数形 | tweet.rb |
| テーブル名 | 先頭は小文字、複数形 | tweets |

Tweetクラスがtweetsテーブルを操作でき、モデルクラスが入ったファイル名はtweet.rbとなる。
モデルとテーブルの設計図の生成
モデルとテーブルは1つのコマンドで同時に作成することができる。
rails g model コマンド
rails g modelコマンドを使用すると、DBにテーブルを作成するためのファイルとそのテーブルに対応するモデルファイルとを自動で作成することができる。実際に使用する際には「rails g model モデルクラス名(全て小文字)」というように作成したいモデルのクラス名を全て小文字にしたものを後ろに付けて実行する。
ターミナル
1 2 |
$ rails g model モデルクラス名(全て小文字)
# モデルを作成
|
※ターミナルでサーバーを起動している場合は「control + c」でサーバーを止めて行う
ターミナル
1 2 3 4 5 |
正しく作成できれば以下の様な出力結果が表示される。
1 2 3 4 5 6 |
この出力結果の3行目には下記のように書いてある。
1 |
create app/models/tweet.rb
|
これはcreate以下のファイルを新しく作成したことを意味している。作成されたファイルはapp/models/tweet.rbとなっているので、app/modelsというディレクトリにtweet.rbというファイルが作成されたことを意味している。
- app
- models
- tweet.rb
- models
さきほどコマンドを実行する際に、rails g modelのあとにtweetと付けて実行したが、このtweetはモデル名を表しているので、その結果tweet.rbというモデルのファイルが作成された。
rails d model コマンド
モデルを作成する際は「rails g model」コマンドを使用して作成した。この時にモデル名を間違えて作成してしまった場合、「rails d model」コマンドを使用してモデルファイルを削除することができる。
ターミナル
1 2 |
$ rails d model モデル名
# 作成したモデルを削除
|
「rails d model」コマンドを使用する際には間違えて作成したモデル名を後につけて「rails d model」コマンドを実行する。このコマンドで削除を実行すると、モデルを作成した際に自動的に作られた関連ファイルも同時に削除されるので非常に便利。
テーブルの作成
rails g modelコマンドでモデルのファイルを作成した際、同時にそのモデルと結びつくテーブルの設計図も生成されている。これをマイグレーションファイルと呼ぶ。この段階ではまだ、DBには該当するテーブルは存在しない。このマイグレーションファイルを実行することで、初めてテーブルが作られる。
マイグレーションファイル
マイグレーションファイルは、テーブルの設計図。マイグレーションファイルにどんなカラムを持つテーブルにするかを書き込み、実行することでテーブルが作成される。
このマイグレーションファイルは以前に「rails g model」コマンドを実行した際に作成されている。rails g modelコマンドの出力結果の2行目には、以下のようにある。
1 |
create db/migrate/20141011073059_create_tweets.rb
|
create以下が作成されたファイルを示すので、db/migrateというディレクトリにマイグレーションファイルが作成されたことがわかる。
- db
- migrate
- 2014XXXXXXXXXXXX_create_tweets.rb
- migrate
マイグレーションファイルの編集
以下は、マイグレーションファイルの中身の例である。changeというメソッドで、作成するカラムを指定することができる。
db/migrate/2014XXXXXXXXXXXX_create_tweets.rb
1 2 3 4 5 6 7 8 |
class Createテーブル名 < ActiveRecord::Migration[5.2]
def change
create_table :テーブル名 do |t|
t.timestamps
end
end
end
|
カラムの「型」
カラム名を指定するとともに、そこにどんなデータが入るのかを示す「型」も指定する必要がある。以下は、主な型の種類。
| 型 | 説明 | 用例 |
|---|---|---|
| integer | 数字 | ユーザーのidなど |
| string | 文字(少なめ) | ユーザー名、パスワードなど |
| text | 文字(多め) | 投稿文など |
| boolean | 真か偽か | 真偽フラグ |
| datetime | 日付と時刻 | 作成日時、更新日時など |
マイグレーションファイルを編集する
マイグレーションファイルはdb/migrateというディレクトリの中にあるファイルのこと。ファイルは1つだけしか存在していないはずなので、そのファイルを編集する。
- db
- migrate
- 2014XXXXXXXXXXXX_create_tweets.rb
- migrate
db/migrate/2014XXXXXXXXXXXX_create_tweets.rb
1 2 3 4 5 6 7 8 9 10 |
class CreateTweets < ActiveRecord::Migration[5.2]
def change
create_table :tweets do |t|
t.string :name
t.text :text
t.text :image
t.timestamps null: true
end
end
end
|
作成するカラムとその型を、changeというメソッドの中で指定する。
t.に続くのが「型」で、:に続くのがカラム名。
編集を開始する際は7行目のt.timestampsの横に何もないが、null: trueを付け加えている。これは後で行う操作をする上で必須であるため。
マイグレーションファイルの実行
マイグレーションファイルはテーブルの設計図を表しているので、実際にその設計図に従ってテーブルを操作するにはrake db:migrateコマンドを使用する。
rake db:migrate
現在存在している未実行のマイグレーションファイルを実行するコマンド。
ターミナル
1 2 |
$ rake db:migrate
# マイグレーションファイルの実行
|
マイグレーションファイルの編集ができたので、マイグレーションファイルを実行。
ターミナル
1 2 3 4 5 |
コマンドを正しく実行できると、出力結果が表示される。
1 2 3 4 |
== 20141016074753 CreateTweets: migrating ==============================
-- create_table(:tweets)
-> 0.0315s
== 20141016074753 CreateTweets: migrated (0.0317s) =====================
|
スキーマファイル
スキーマファイルは「rake db:migrate」を実行した際に更新が行われ、最新のマイグレーションファイルのバージョンが記録される。tweetsテーブルを作成するためにマイグレーションを実行した。つまり、スキーマファイルにはtweetsテーブルを作成する際に編集したマイグレーションファイルのバージョンが記録されている。
- db
- migrate
- 20150108030707_create_tweets.rb
- migrate
ファイル名の「20150108030707」の部分がマイグレーションファイルのバージョンを示している。
ここには現在の日時の情報が入るので、実際に作成されたものとは名前は異なる。
- db
- schema.rb
db/schema.rb
14 15 16 17 18 19 20 21 22 23 24 |
ActiveRecord::Schema.define(version: 20150108030707) do
create_table "tweets", force: :cascade do |t|
t.string "name"
t.text "image"
t.text "text"
t.datetime "created_at"
t.datetime "updated_at"
end
end
|
14行目の部分で、version:のあとに20150108030707とある。これが現在の最新のマイグレーションファイルのバージョンを示している。今回はtweetsテーブルを作成するマイグレーションファイルの実行が最後のマイグレーションなので、このバージョンが一致している。
schema_migrations
schema_migrationsとはデータベースの変更履歴のようなもので、どのマイグレーションファイルまでが実行されているかが記録されていくテーブル。マイグレーションファイルが実行された際に自動的に作成される。
schema_migrationsを確認するために、Sequel Proを利用する。
注意
マイグレーションファイルは消してはいけない。実行し終わったマイグレーションファイルを削除してしまうと、schema_migrationsと齟齬が生じ問題が生じる恐れがある。
テーブルを確認する
作成したテーブルを確認するのに、MacではSequelproというアプリケーションを利用する。
Sequel Pro
Sequel Pro(シークエルプロ)は、テーブルを見やすく表示してくれるアプリケーション。データベースに接続し、見たいテーブルを選択するとエクセルのような形式で表示してくれる。
Sequel Proを起動して、「localhost」に接続
左上にある「データベースを選択」から「pictweet_development」を選択。
すると、以下のように左側に表示されるテーブル一覧に「tweets」と「schema_migrations」が表示されているはず。

「schema_migrations」を選択し、下記のように「内容」を選択。

先ほど実行したマイグレーションファイルの名前の数字の部分がレコードとして記録されていることがわかる。

rake db:migrateコマンドを実行すると、まずschema_migrationsを参照し、実行されていないmigrationファイルがあるかどうか調べ、あればそれを実行する。
そのため、rake db:migrateを複数回実行しても、同じmigrationファイルが再度実行されることはない。また、一度実行されたmigrationファイルの中身を変更してもそれは実行されない。
一度変更したデータベースの状態を元に戻す
rake db:migrateコマンドを実行した際、読み込んだmigrationファイルの記述が間違っていて、意図しない名前や型を持つテーブルができてしまうような場合は、rake db:rollback コマンドを利用する。
誤った名前のカラムを追加してしまった時は、実行したマイグレーションファイルを書き換えて再度 rake db:migrateすれば良いと思うかもしれないが、その方法では正しいカラムを作り直すことはできない。
なぜなら、railsではマイグレーションを一度実行してしまうと、そのマイグレーションを編集して再度マイグレーションを実行することができないからだ。
rake db:rollback
これから先新たなテーブルを作成したり、カラムの追加などテーブルに変更を加える際は常にmigrationファイルを作成する。rake db:rollbackコマンドを実行すると、データベースの状態が最新のmigrationファイルを実行する前に戻る。
ターミナル
1 2 3 4 5 |
成功すれば、続いてターミナルに以下のように表示される。
1 2 3 4 |
== 20150108030707 CreateTweets: reverting =====================================
-- drop_table(:tweets)
-> 0.0260s
== 20150108030707 CreateTweets: reverted (0.0293s) ============================
|
先ほど作成したのはtweetsテーブルを作成するマイグレーションファイルなので、rollbackした場合はtweetsテーブルが消えるはず。
もう一度Sequel Proを起動し確認してみる。

左上の「データベースを選択」から、「pictweet_development」を選択する。
tweetsテーブルが消えていることがわかる。
また、「schema_migrations」テーブルを確認すると、先ほどの記録が消えて何もレコードが無い状態になっている。このように、rake db:rollbackコマンドを実行すると最後に行われたマイグレーションファイルの実行が無かったことになるが、migrationファイル自体は残る。なので、もう一度rake db:migrateコマンドを実行すれば再びtweetsテーブルが作成される。
ターミナル
1 2 3 4 5 |
続いてターミナルに以下のように表示されれば成功。
1 2 3 4 |
== 20141016074753 CreateTweets: migrating ==============================
-- create_table(:tweets)
-> 0.0315s
== 20141016074753 CreateTweets: migrated (0.0317s) =====================
|
テーブルの操作
アプリケーションを利用してレコードを追加
tweetsテーブルにレコードを、今回はプログラミングは利用せず、アプリケーションから直接追加する。
Sequel Proを起動して、「localhost」に接続
以下を参考に、テーブルを表示

接続に成功すると、以下のような画面が表示される。
上部に「id」「text」「created_at」・・・と続いているのがカラム。カラムのうち「id」はレコードの番号で、自動で作成される。「created_at」「updated_at」は、マイグレーションファイルのt.timestampsという記述によって作成されている。

一番下の「+」ボタンを押すと空のレコードが作成される。編集したいレコードのカラムをダブルクリックすると以下の入力画面が表示されるので、「name」「text」のカラムを編集する。
以下を参考に3つレコードを作成し、それぞれの「name」「text」に適当に値を入れる
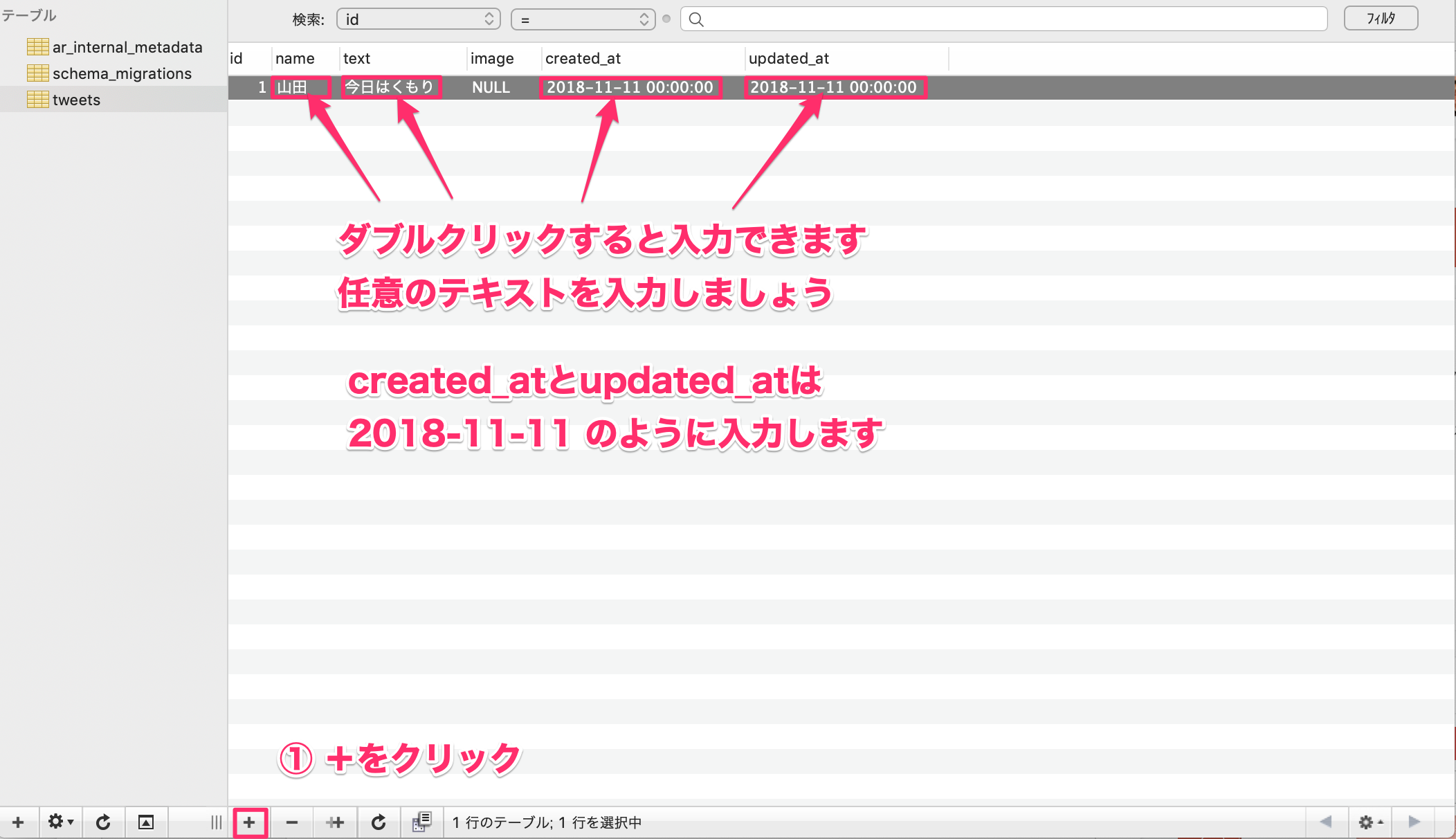
created_atとupdated_atのカラムが空欄だとエラーになってしまうため、必ず入力する。
以下のようにレコードが3つ作れていれば完成。

コンソールでの操作
Railsには、ターミナルからRails内で定義されているメソッドの確認を行うことができる機能が備わっている。これを、コンソールと呼ぶ。
コンソールからレコードの情報を呼出す
rails c コマンド
rails c とは「rails console」(コンソール)の略です。コンソールを実行すると作成したRailsアプリケーションのメソッドやクラスなどを実際に呼び出すことができる。ターミナルから「rails c」コマンドを実行することでコンソールを起動できる。
ターミナル
1 2 3 4 |
$ rails c
# コンソールの起動
[1] pry(main)>
|
コンソールを起動するとpryと表示され、この横にメソッドなどを書いていくことができる。コンソールを終了するには、コンソール上で「exit」と入力しエンターキーを押す。
ターミナル
1 2 3 |
[1] pry(main)> exit
# exitと書きエンターキーで実行(ターミナルに戻る)
$
|
慣れないうちは、ターミナルで実行すべきコマンドをコンソールで実行してしまいエラーが出る、ということが良くある。自分が実行するコマンドはターミナルで実行するものなのか、コンソールで実行するものなのかをよく確認する。
テーブルの情報をRails側で利用する方法
あるテーブルに保存されているレコードの情報を取得するには、名前によって関連付ける必要がある。
例えば、tweetsテーブルに保存されているレコードの情報を利用するためにはTweetクラスを用意する必要があるが、rails g model コマンドを利用することでこれらを一度に生成できる。
テーブルと、関連するモデルクラスがある現在の状態であれば、コンソール上から実際にコードを書いてテーブルの情報を取得する方法を試すことができる。
tweetsテーブルからidカラムの値が1であるレコードのnameカラムの情報を取得するには以下のようにする。
1 2 3 4 |
1行目は、Tweetクラスのfindメソッドを利用しているかたち。
すると、返り値はtweetsテーブルのカラム名をプロパティとして持つTweetクラスのインスタンスとなる。
この時各プロパティの値は、該当レコードのカラムの値と一致する。今回の場合は、idカラムが1のレコードの値。
1行目によって定義された変数tweetにはTweet.find(1)によって得られた返り値である上記のTweetクラスのインスタンスが代入されている。ここから各カラムの情報を取得したい場合は、2行目のようにカラム名をメソッドとして書く。
ActiveRecordの仕組み
なぜ定義されていないfindというメソッドが使えるの?
実は、rails g modelコマンドで生成されるモデルクラスは全てApplicationRecordというクラスを継承している。
ActiveRecord
ActiveRecord(アクティブレコード)はRubyのGemの一種。このGemはモデルとテーブルをつなぎ合わせることで、Railsからテーブルのレコードにアクセスできるようにする。ActiveRecordはRailsにデフォルトでインストールされている。実際に、この機能を利用する際にはApplicationRecordというクラスを継承して使用する。
例えば、今回生成しているtweet.rb。
tweet.rbの1行目に< ApplicationRecordとある。<マークはマークの右に書かれたクラスを継承していることを示しているので、TweetクラスはApplicationRecordを継承していることになる。Tweetクラスはモデルクラスだが、このクラスがデータベースにアクセスすることができるのは、ApplicationRecordを継承しているから。
もう少し正確に言うと、ApplicationRecordというクラスにはテーブルにアクセスして情報を取得するためのメソッドが定義されており、モデルクラスはそれを継承し利用することでテーブルから情報を取得している、ということになる。
クラスの継承
あるクラスに定義されたメソッドを、別のクラスで利用できるようにすることを継承と言う。
以下の図において、
元となるクラスを親クラス、親クラスのメソッドを引き継ぎ新しく作成するクラスを子クラス とする。
allメソッドやnewメソッドは、ApplicationRecordクラスのメソッドである。

現在ApplicationRecordクラスを継承しているのは、Tweetクラスのみ。またTweetクラスにはまだメソッドが定義されていないので、現在Tweetクラスで用いる事ができるのは継承しているApplicationRecordクラスのメソッドだけである。
ApplicationRecordメソッドの使用
モデルクラスはApplicationRecordというクラスを継承している。クラスを継承した場合、継承元のクラスで定義されているメソッドを利用することができる。このとき継承元であるApplicationRecordで定義されているメソッドのことを「ApplicationRecordメソッド」と言う。ApplicationRecordはデータベースにアクセスするためのクラスなので、そのメソッドもデータベースへのアクセスを行うものになっている。
・allメソッド
・newメソッド
・saveメソッド
・createメソッド
(その他たくさんある)
allメソッド
allメソッドはApplicationRecordを継承したモデルと結びつくテーブルのレコードを全て取得する。
コンソール
1 |
[1] pry(main)> Tweet.all
|
以下はコンソールからallを実行した場合の例。ApplicationRecordを継承しているTweetクラスのクラス・メソッドのように利用する。

また、コンソールからallを実行した場合下記の最後のように「:」と表示され次のコマンドが打てなくなる現象がある。
これはターミナルの表示領域がいっぱいになってしまうためで、「Q」 を押すと次のコマンドが打てるようになる。
ターミナル
1 2 3 4 5 6 7 8 9 10 11 |
[1] pry(main)> Tweet.all
Tweet Load (16.8ms) SELECT `tweets`.* FROM `tweets`
=> [#<;Tweet:0x007fad47a6b1b0 id: 1, text: "こんにちは!", created_at: nil, updated_at: nil, name: "ken", image: nil>;,
#<;Tweet:0x007fad42928050 id: 2, text: "また明日!", created_at: nil, updated_at: nil, name: "mami", image: nil>;,
#<;Tweet:0x007fad47a6bae8 id: 4, text: "おはよう!", created_at: nil, updated_at: nil, name: "takumi", image: nil>;,
#<;Tweet:0x007fad47a6ad28 id: 5, text: "プログラミング好き!", created_at: nil, updated_at: nil, name: "takumi", image: nil>;,
#<;Tweet:0x007fad47a6b688 id: 6, text: "Ruby!", created_at: nil, updated_at: nil, name: "takumi", image: nil>;,
#<;Tweet:0x007fad47a6a850 id: 7, text: "on!", created_at: nil, updated_at: nil, name: "takumi", image: nil>;,
#<;Tweet:0x007fad47a6a238 id: 8, text: "Rails!", created_at: nil, updated_at: nil, name: "takumi", image: nil>;,
#<;Tweet:0x007fad42928668 id: 9, text: "どうも!", created_at: nil, updated_at: nil, name: "takumi", image: nil>;,
:
|
これでTweetsテーブルの全てのレコードをターミナル上に表示することができたここで取得できたレコードが一つ一つがどのように表示されているのか。
ターミナル
1 |
idが1のTweetのレコードを見た時、その中にはidやtextなどのカラムの値が表示されている。これを見ることで、ApplicationRecordに定義されたメソッドを利用して取得してきたそのレコードのカラムの値などを確認することができる。
ちなみにこの「#<Tweet:~」以降に続いている「0x007fad47a6b1b0」という番号は オブジェクトidと呼ばれるもので、mysqlサーバー内でそのレコードおよびインスタンスを識別するための名前のようなもの。
newメソッド・saveメソッド
newメソッドはクラスのインスタンスを生成するメソッド。ApplicationRecordを継承しているモデルクラスの場合、newメソッドを実行すると関連するテーブルのカラム名がキーになったハッシュのようなものが生成される。これをモデルクラスのインスタンスと呼ぶ。インスタンスのそれぞれのキーに値を代入してsaveメソッドを実行するとテーブルに保存される。
ターミナル
1 2 |
以下はコンソールからレコードを保存した場合の例。
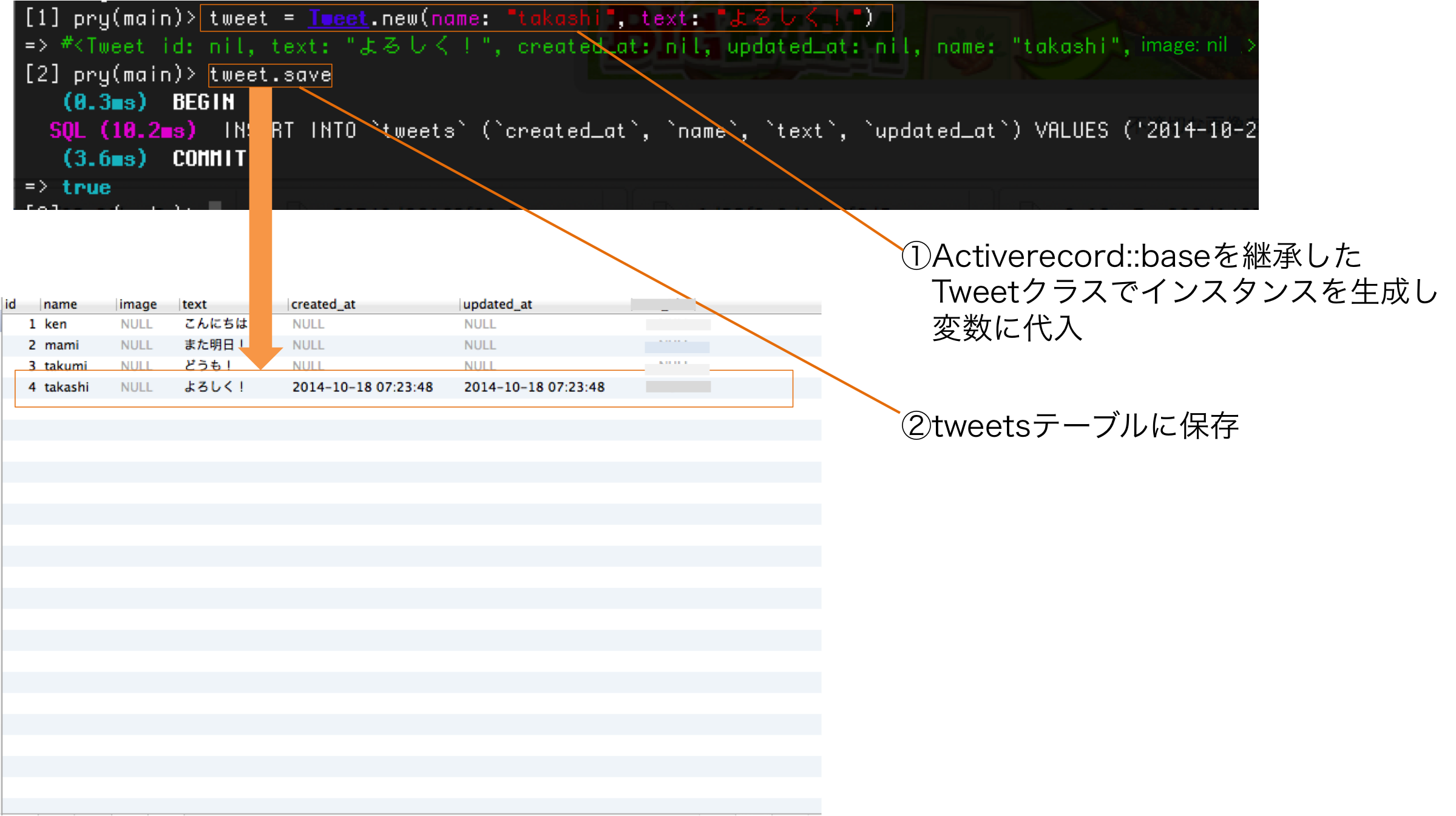
保存されたレコードを見ると、生成されたインスタンスに引数として渡したハッシュのキーがカラム名、バリューがその値となっていることが確認できます。
createメソッド
createメソッドはレコードの作成を行うことのできるメソッド。newメソッドとsaveメソッドを使用して行った処理をcreateメソッドで一気に行うことができるので、単にレコードを作成する場合にはこのメソッドを使用する。下記の例1と例2は同様の作業を行っている。
例1:
コンソール
1 2 |
例2:
コンソール
1 |
[1] pry(main)> Tweet.create(name: "takashi", text: "Nice to meet you!")
|
SQL(エス・キュー・エル)
SQLとは、データベースに対して保存されているデータを要求する時に使用する言語の形式。
本来ならデータベースに対しては以下のようなSQL文を使ってデータを要求しなければならないが、railsではActiveRecordのおかげで簡単にデータを要求することができる。
例1:
1 |
SELECT `tweets`.* FROM `tweets`
|
例2:
コンソール
1 |
[1] pry(main)> Tweet.all
|
上記の例1と2は同じ処理を行っている。Railsでは例2のように記述するだけで、データベースにアクセスする際には自動的に例1のようなSQL文に変換される。このように、ActiveRecordを使用するRailsではより直感的で短い記法でテーブルの情報を操作することができる。
そのままコンソールで「Tweet.all」とコマンドを打つと、呼び出されたデータは、ターミナル上に表示される。Tweetはクラス名で、allはテーブルに保存されたデータを全て呼び出すというメソッド。
コンソール
1 2 |
[1] pry(main)> Tweet.all
# tweetsテーブルの全てのレコードを取得する
|
以下のような出力結果が表示されれば、モデルとデータベースは正常に動作している。
コンソール
1 2 3 4 5 |
[1] pry(main)> Tweet.all
Tweet Load (0.6ms) SELECT `tweets`.* FROM `tweets` LIMIT 4
=> [#<;Tweet id: 1, text: "こんにちは!", created_at: nil, updated_at: nil, name: "ken", image: nil>;,
#<;Tweet id: 2, text: "また明日!", created_at: nil, updated_at: nil, name: "mami", image: nil>;,
#<;Tweet id: 3, text: "どうも!", created_at: nil, updated_at: nil, name: "takumi", image: nil>;]
|
2行目に、SELECT ~ と続いているのがSQL文。SQL文も、以下の手順で実際に利用。
以下の手順に従い、Sequel proでSQL文を使用する

⑤の操作の後、以下のように表示されれば成功。Tweet.allで取得したレコードと同じものが取得されたことが確認できる。

参考書参照
「プロになるためのWeb技術入門」p219 ~, 項6.6
コンソールからレコードを作成
コンソールからレコードを作成するにはcreateメソッドを使用する。
コンソール
1 2 |
[2] pry(main)> Tweet.create(name: "takashi", text: "Nice to meet you!")
# 新しいレコードの作成
|
Sequel proを起動し、tweetsテーブルを確認
以下のように、tweetsテーブルに新しくレコードが追加されていればOK。

(Windowsの場合) HeidiSQLで、tweetsテーブルを確認
以下のように、tweetsテーブルに新しくレコードが追加されていればOK。

コンソールからテーブルの情報を更新
ActiveRecordを利用して、あるテーブルのレコードの情報を更新する。
以下はその例。
まずは、テーブルからレコードを一つ取り出し、変数tweetに代入。
今回はfindメソッドを使用する。
findメソッド
findメソッドは引数に指定したidにあたる作品情報を1件だけ取得。 もし、そのidにあたる作品が存在しない場合、エラーが発生。
コンソール
1 2 3 |
この時、変数tweetにはApplicationRecordというクラスを継承したTweetクラスのインスタンスが代入されることになる。
ターミナルで表示されている=>以降を見ると、tweetsテーブルのカラムとそのレコードが保持しているそれぞれのカラムの値がハッシュ形式で表示されている。
さらに、以下の例のようにすることで、このtweetの持つカラムの値を更新することができる。
コンソール
1 2 3 |
レコードの更新
テーブルに保存されているレコードを更新するにはそのレコードをインスタンスとして取得し、カラムを指定して値を直接代入する。上書きするだけではレコードの値は更新されないので、上書きを保存するにはインスタンスのsaveメソッドを使う。
idが1のユーザーのnameを"Shinbo"から"Abe"に更新
1 2 3 4 5 6 7 |
user = User.find(1) # Usersテーブルのidが1のレコードを取得
puts user.name
=> "Shinbo" # nameカラムの値は"Shinbo"
user.name = "Abe" # nameカラムの値を"Abe"に上書き
user.save # 変更をデータベースに反映
puts user.name
=> "Abe" # nameカラムの値が"Abe"に更新された
|
saveメソッドを呼び出すまではインスタンスの値が更新されてはいるが、データベース上には保存されていない状態。データベースに更新を反映させるときは忘れずにsaveメソッドを使う。
【作業】レコードを更新手順
①コンソールを起動
ターミナルからrails cコマンドでコンソールを立ち上げる。
②tweetsテーブルからidが1のレコードを取得し、変数に代入
コンソールで以下のように書き、実行。
コンソール
1 2 3 |
③取得したレコードのtextカラムの中身を、「さようなら!」に更新
コンソールで以下のように書き、実行。
コンソール
1 2 |
pry(main)> tweet.text = "さようなら!"
#取ってきたレコードのtextカラムを、"さようなら"という値に上書き
|
④上書きしたレコードを再度保存
コンソールで以下のように書き、実行。
コンソール
1 2 |
pry(main)> tweet.save
#上書きしたレコードを再保存
|
以上で、tweetsテーブルにあるidが1のレコードのtextカラムを「さようなら!」に更新することができる。
最後に、もう一度レコードを取得し、正しく上書きできているか確認する。
コンソール
1 2 3 |
textの値が"さようなら!"になっていることがわかる。